
hal0 · Local AI for the Ultimate Homelab
Strix Halo native AI inference, image gen & agents for homelabs.
Your Strix Halo box, running real /v1/* inference
hal0 turns a Linux box — ideally a Ryzen AI Max+ 395 — into a private, OpenAI-compatible AI appliance. One /v1/* API across every modality, with concurrent workloads the box manages for you. One command installs the lot.
curl -fsSL https://hal0.dev/install.sh | bash
Not another llama-server wrapper — it's the orchestration around one. Stop running models from a chat tab; run one service for the whole local AI stack.
What's in the org
We publish the models, quants, and artifacts that ship with hal0 — tuned for AMD Strix Halo (Ryzen AI Max) and the ROCm stack.
| Model | What it is |
|---|---|
| FastContext-Hal0-4B-ROCmFP4 | 4B fast-context chat model, quantized to ROCmFP4 for Strix Halo iGPU inference. |
More quants and companion models landing as hal0 ships. Watch the org to get pinged.
One /v1/* surface, five providers
Drop-in for any OpenAI SDK — point your client at :8080/v1 and go. Chat, completions, embeddings, reranking, speech-to-text, text-to-speech, and image generation, all behind one API the box schedules for you.
| Provider | Backend | Workload |
|---|---|---|
| llama.cpp | Vulkan / ROCm / CUDA | chat, embed, rerank, vision |
| FLMv1 | AMD XDNA NPU | chat, embed |
| FLM / Whisper v3 turbo | XDNA NPU | speech-to-text |
| Kokoro-82M | CPU / Vulkan | text-to-speech (54 voices) |
| ComfyUI v1 | ROCm | image gen (SDXL / SD 1.5 / Flux) |
Strix Halo native. Not Strix-Halo-only — also runs on Ryzen AI Max 385/390, NVIDIA RTX 30/40/50, AMD Radeon RX 7000, and CPU-only x86_64 fallback.
The operator console
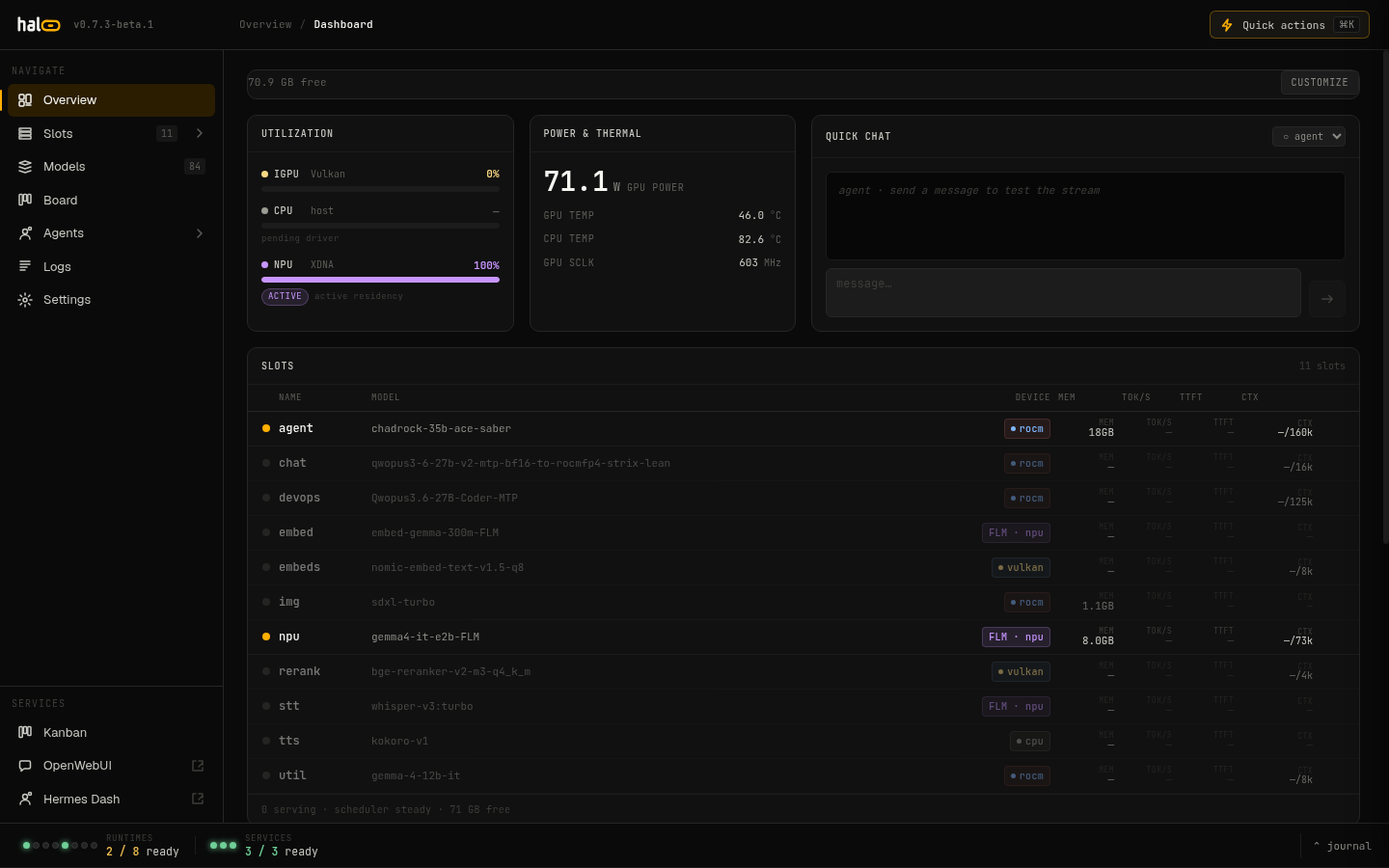
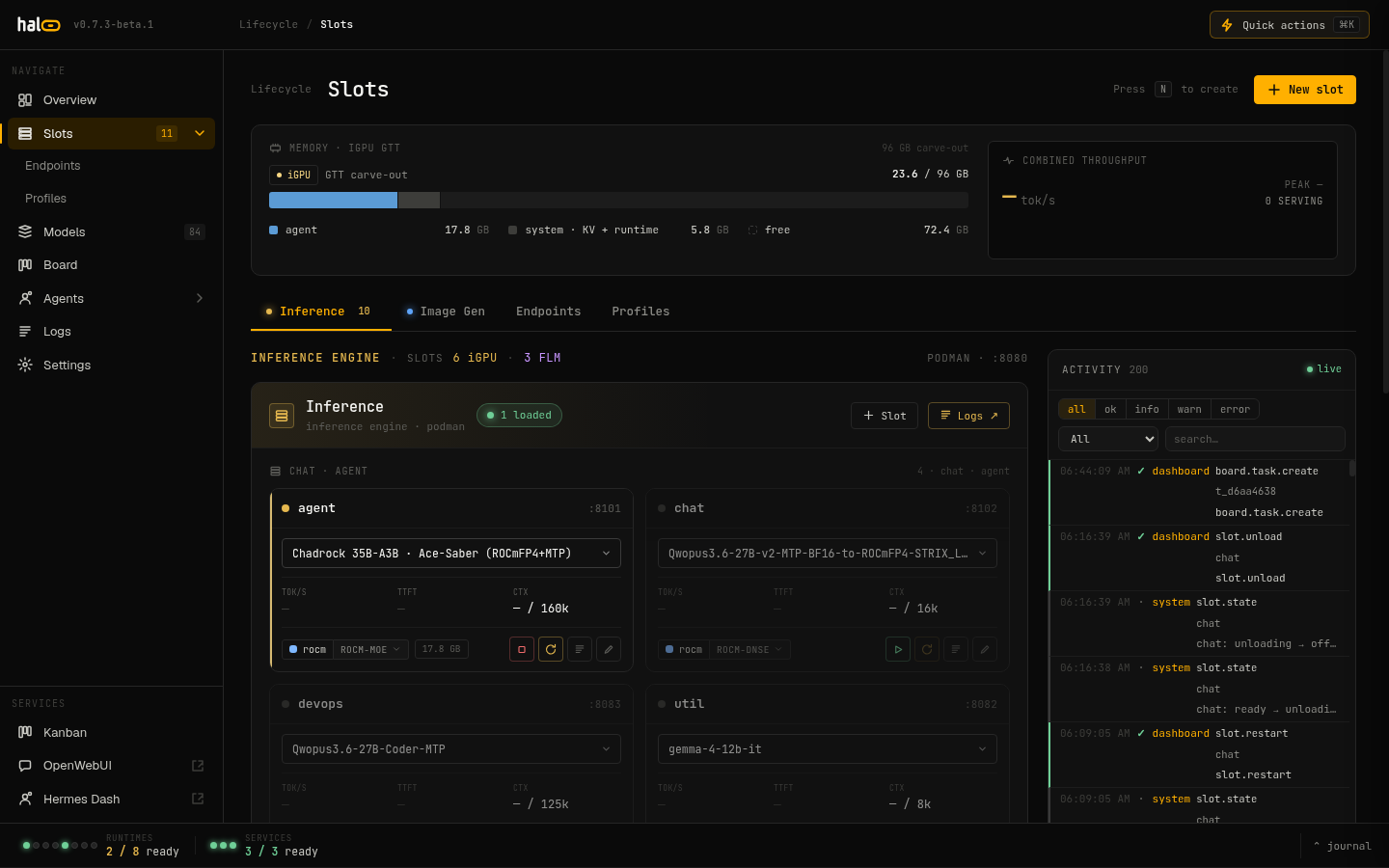
Dark-by-default React admin UI with SSE-backed status and a live log tail — see slots, throughput, and service health at a glance.
 |
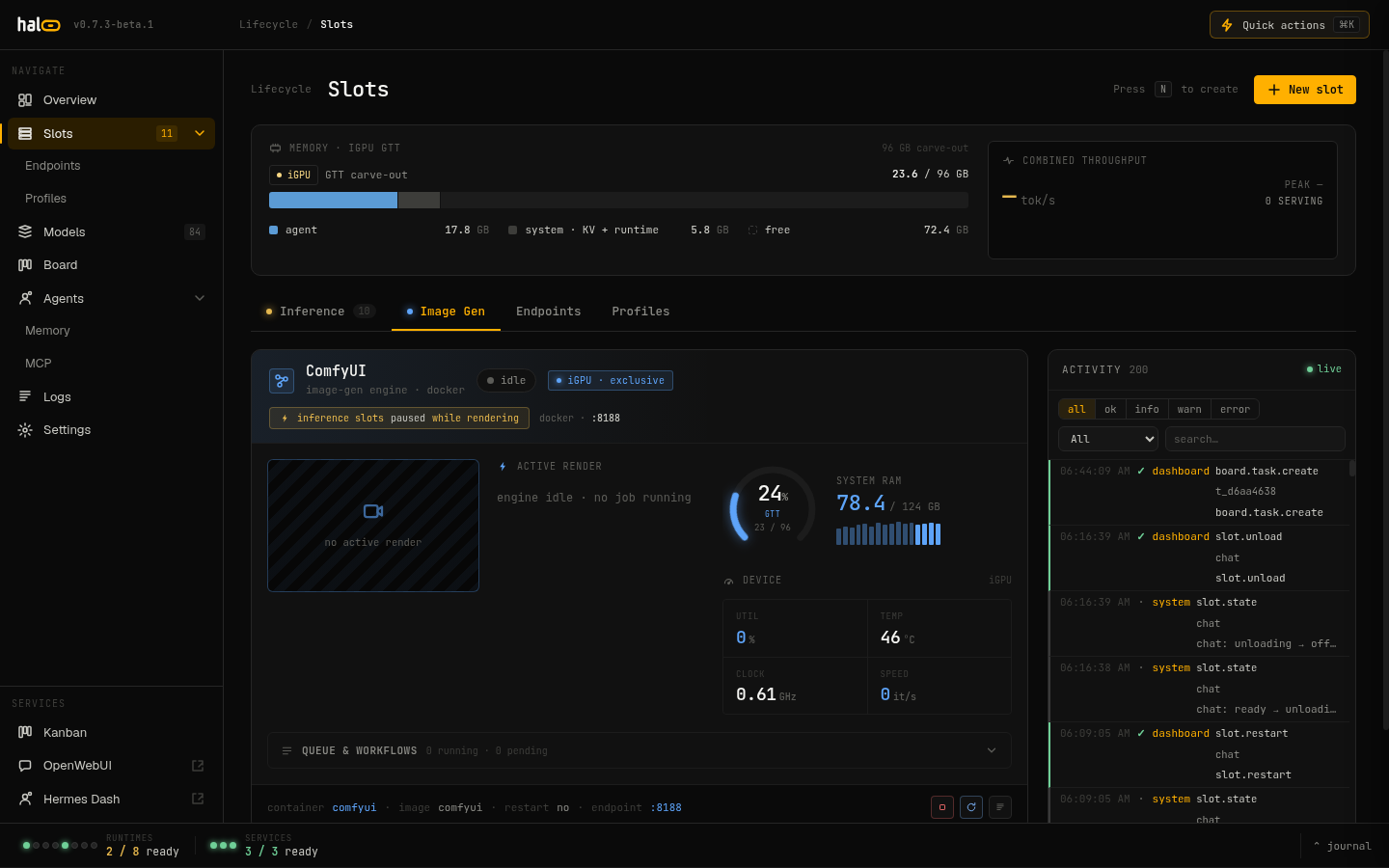 |
| Slots — per-slot state & the typed inference lifecycle | Image gen — ComfyUI on the iGPU, inference slots paused |
 |
 |
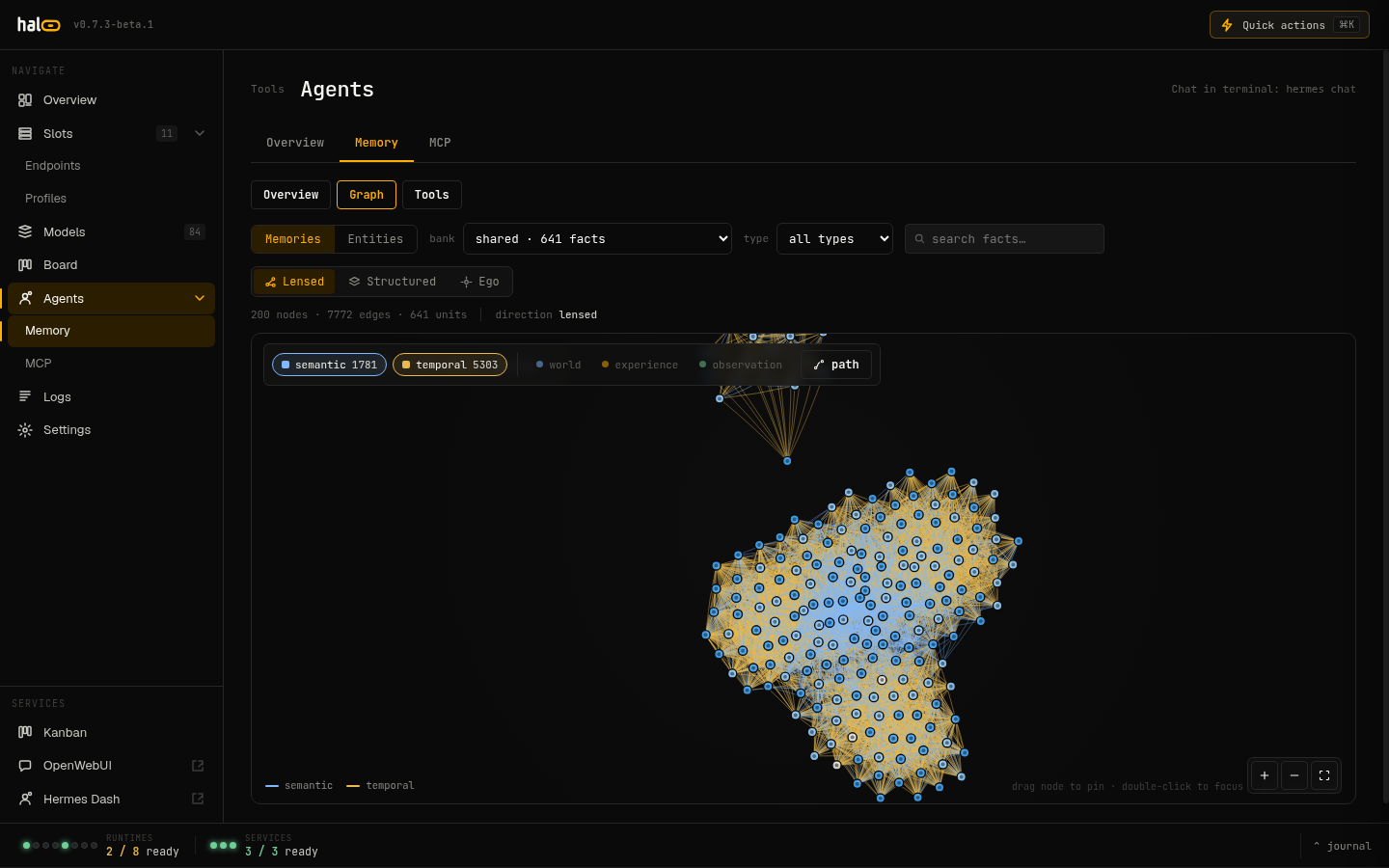
| Memory graph — semantic + temporal knowledge graph | Hermes — the bundled, self-bootstrapping agent |
Performance (Ryzen AI Max+ 395, 128 GB)
| Metric | Number |
|---|---|
| Primary + embed, concurrent | 258 tok/s |
| Primary model serving | 142 tok/s |
| Dispatch latency (p50) | 174 ms |
Meet Hermes
Hermes installs and bootstraps itself on first run — sandboxed under its own user, prewired to the local /v1 API and your MCP servers, with tool-approval gating. The agent that comes home already plugged in.
Get started
- 🚀 Install:
curl -fsSL https://hal0.dev/install.sh | bash(Linux x86_64, Python ≥ 3.12) - 📖 Docs: hal0.dev/docs/getting-started
- 💻 Source: github.com/hal0ai/hal0
- ✉️ Say hi: hello@hal0.dev
Apache-2.0 · Linux + systemd · no telemetry by default · cosign-signed releases
★ Follow the org to get new models and quants in your feed as hal0 ships.